My work to clean up FracFocus requires curation. By that, I mean manually looking at data and making decisions about how to deal with it based on its values. Data analysts have to do that all the time: is this value an outlier? should I transform the data? Should I drop these values because they seem to be not collected in the same way as the rest?
The work on FracFocus is different in at least two ways: First, I am not making decisions for a particular analysis goal, but rather just the goal of producing a “clean set” for unspecified future analysis. And second, the data set is constantly growing so that I have to either 1) make decisions that may affect future (unknown) data so that I can “reuse” my decisions for older data on new materials or 2) curate the entire data set every time it is updated. I’m currently working on how to deal with CAS registry numbers, and that is a good example of both issues.
Simply put, CAS numbers are codes that uniquely identify chemical compounds, whereas the “names” we give chemicals are rife with ambiguity (for instance, there are dozens of ways of naming 144-55-8: baking soda). FracFocus wisely tells end-users to pay attention to the CAS number and not the name, because the FracFocus data are messy. And because it is messy, we must either throw data out that doesn’t conform or try to correct it.
So for the current data set (March 2021), even though there are only about 1,400 actual unique chemicals, there are about 3900 unique values in the field CASNumber that have to be curated – that is, decide on our best guess for the “real” CAS number for that raw CASNumber. For a large proportion of those 3,900, the answer is simple: either they match an authoritative CAS number exactly or they are clearly not even CAS numbers. For those, the curation is easy and any new data added in the future won’t change what I decide for the current values. But some require cleanup before they match a reference CAS number. Some require an interpretation that is data dependent. The CAS number for water is ‘7732-18-5’ and there are scads of those in the data. However, there are also some ‘7332-18-5′ versions, that after examining individual records, are clearly also water. Do we make all future versions of 7332-18-5 into water? I wouldn’t feel good about that. However, if we also had the IngredientName and it was ‘water’ for all those future versions, I would be comfortable making that call.
But throwing the second variable into the curation process adds a huge curation cost. We go from 3,900 unique CASNumber values to 33,000 unique CASNumber/IngredientName pairs. Whew! That’s a lot of labor, though we can probably cut down how much it requires by only focusing on the CAS Numbers that are ambiguous.
Ok, lets say that the first curation task is manageable; even though it might take a week of work, if you only have to do it once, that’s doable. But there is also the question about how much ongoing work would a CASNumber/IngredientName evaluation take? FracFocus is an ever expanding entity and we need to grapple with the future work, too.
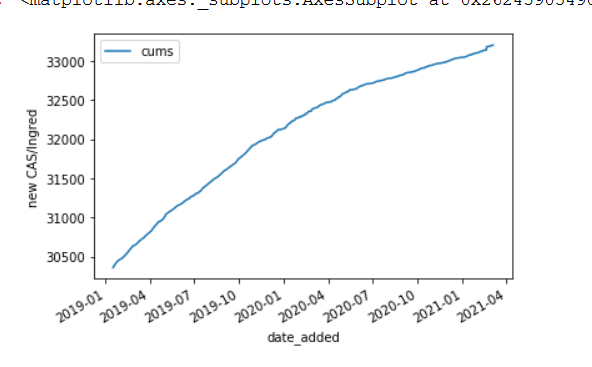 Currently, it looks like about 50 new combinations a week. In 2019, the rate was higher and it is likely to go back to that, at least. That seems reasonable, if there are tools in place that make the regular curation task simple. Especially if I can make the default to not accept the record and to make the rules very clear. I am willing to give it a try. Going back to a simpler curation task (just using CASNumber) is relatively easy.
Currently, it looks like about 50 new combinations a week. In 2019, the rate was higher and it is likely to go back to that, at least. That seems reasonable, if there are tools in place that make the regular curation task simple. Especially if I can make the default to not accept the record and to make the rules very clear. I am willing to give it a try. Going back to a simpler curation task (just using CASNumber) is relatively easy.