**For a video introduction to our lab’s research, click here!
Our brains construct rich perceptual experiences from the rawest of visual inputs: spots of light hitting different places on our eyes. In a fraction of a second, we integrate this information to recognize objects, deduce their locations, and plan complex actions and behaviors. But although visual perception feels smooth and seamless, this process is far more complex than it appears. Our lab studies human behavior and brain function to investigate how visual properties such as color, shape, and spatial location are perceived and coded in the brain, and how these representations are influenced by eye movements, shifts of attention, and other dynamic cognitive processes.
We use a variety of tools in our lab, including neuroimaging (fMRI & EEG), gaze-contingent eye-tracking, human psychophysics, and computational analyses. Below are some links to papers from the lab on the topics of: Visual perception and attention across eye movements, Linking object identity and location, Neural representations for visual processing, and Interactions between attention and working memory. Links to all papers from the lab can be found in Publications, and code for our computational model-based projects can be found on our lab Github.
Visual perception and attention across eye movements
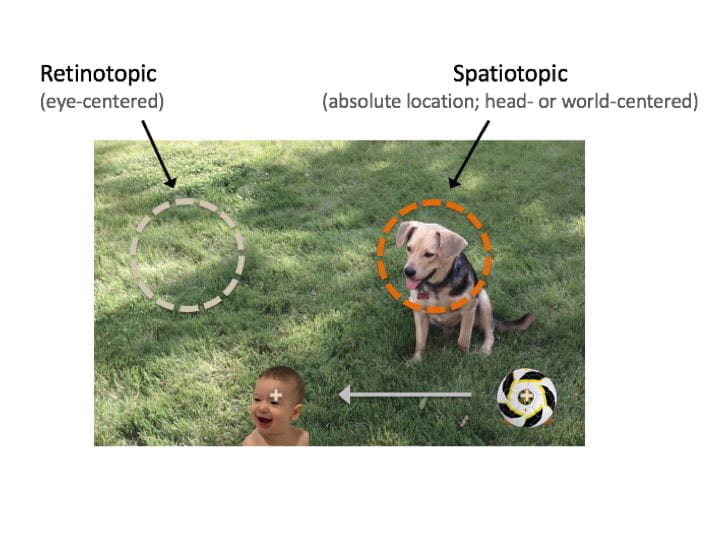 When we move our eyes to explore the world – as we do multiple times each second – the images sent to our brain are erratic snapshots, much like watching a movie filmed by a shaky cameraman. Yet the world does not appear to “jump” with each eye movement; instead we perceive a stable, seamless experience. How do our brains achieve this feat? And what can we learn when it fails? A central theme of our research is that retinotopic (eye-centered) representations are the native language of the visual system, and successful perception requires constant updating of visual information with each eye movement. Much of this research stems from a paradoxical phenomenon we discovered called the “retinotopic attentional trace”: even when required by the task to remember a spatiotopic (world-centered) location, subjects’ attention briefly persists at the (wrong) retinotopic location after an eye movement. This process can have fundamental implications for spatial attention and memory as well as feature/object perception, as described in our “dual-spotlight theory” of remapping. Check out these papers:
When we move our eyes to explore the world – as we do multiple times each second – the images sent to our brain are erratic snapshots, much like watching a movie filmed by a shaky cameraman. Yet the world does not appear to “jump” with each eye movement; instead we perceive a stable, seamless experience. How do our brains achieve this feat? And what can we learn when it fails? A central theme of our research is that retinotopic (eye-centered) representations are the native language of the visual system, and successful perception requires constant updating of visual information with each eye movement. Much of this research stems from a paradoxical phenomenon we discovered called the “retinotopic attentional trace”: even when required by the task to remember a spatiotopic (world-centered) location, subjects’ attention briefly persists at the (wrong) retinotopic location after an eye movement. This process can have fundamental implications for spatial attention and memory as well as feature/object perception, as described in our “dual-spotlight theory” of remapping. Check out these papers:
- Theoretical Reviews
- Spatial attention & perception
- The native coordinate system of spatial attention is retinotopic
- Attentional facilitation throughout human visual cortex lingers in retinotopic coordinates after eye movements
- Attention doesn’t slide: Spatiotopic updating after eye movements instantiates a new, discrete attentional locus
- Robustness of the retinotopic attentional trace after eye movements
- Spatial priming in ecologically relevant reference frames
- Target localization after saccades and at fixation: Nontargets both facilitate and bias responses.
- The native coordinate system of spatial attention is retinotopic
- Memory
- Feature & object perception
- Feature-binding errors after eye movements and shifts of attention
- Object-location binding across a saccade: A retinotopic Spatial Congruency Bias
- No evidence for automatic remapping of stimulus features or location found with fMRI
- The Binding Problem after an eye movement
- Dynamic saccade context triggers more stable spatiotopic object-location binding
- Action
Linking object identity and location
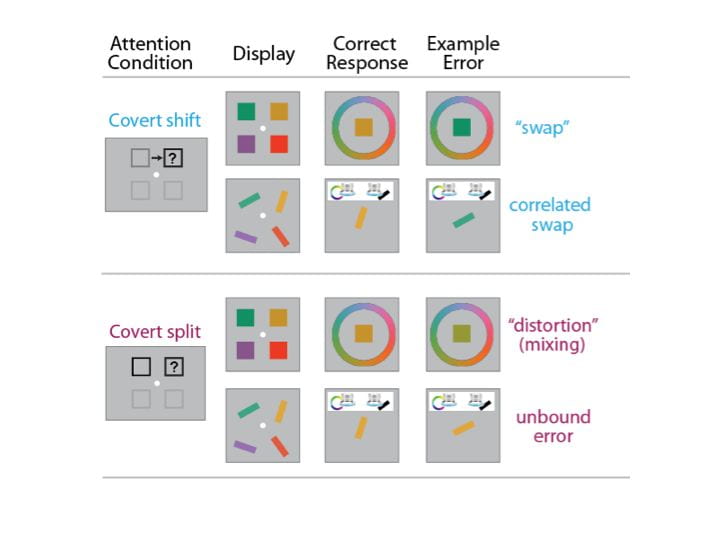 A second line of research focuses on another fundamental challenge of visual stability: How does our visual system combine information about objects’ features and identities with their locations? And how is this what-where binding affected when the “where” information needs to be updated? Work in the lab has uncovered two novel phenomena along these lines. First, when spatial attention is split across two different locations (as in divided attention or during remapping across eye movements), features from objects at these two locations can blend together, resulting in feature-mixing errors. Second, an object’s location plays such a special role during object recognition that it is automatically bound to feature/identity representations, resulting in a “Spatial Congruency Bias” where people are more likely to judge two sequential objects as the same shape, color, orientation, or even facial identity when they were presented in the same location. Ongoing work in the lab is using both feature-mixing and Spatial Congruency Bias paradigms as tools to explore a variety of theoretical questions about object-location interactions. Check out:
A second line of research focuses on another fundamental challenge of visual stability: How does our visual system combine information about objects’ features and identities with their locations? And how is this what-where binding affected when the “where” information needs to be updated? Work in the lab has uncovered two novel phenomena along these lines. First, when spatial attention is split across two different locations (as in divided attention or during remapping across eye movements), features from objects at these two locations can blend together, resulting in feature-mixing errors. Second, an object’s location plays such a special role during object recognition that it is automatically bound to feature/identity representations, resulting in a “Spatial Congruency Bias” where people are more likely to judge two sequential objects as the same shape, color, orientation, or even facial identity when they were presented in the same location. Ongoing work in the lab is using both feature-mixing and Spatial Congruency Bias paradigms as tools to explore a variety of theoretical questions about object-location interactions. Check out:
- Dynamic spatial attention & feature-binding errors:
- Feature-binding errors after eye movements and shifts of attention
- Divided spatial attention and feature-mixing errors
- Object feature binding survives dynamic shifts of spatial attention
- The Binding Problem after an eye movement
- Attentional capture alters feature perception
- Shifting Expectations: Lapses in Spatial Attention are Driven by Anticipatory Attentional Shifts
- Probabilistic visual attentional guidance triggers “feature avoidance” response errors
- Suppression of a salient distractor protects the processing of target features
- Dynamic saccade context triggers more stable spatiotopic object-location binding
- Feature-binding errors after eye movements and shifts of attention
- Spatial congruency bias
- The influence of object location on identity: A “spatial congruency bias”
- Binding object features to locations: Does the “Spatial Congruency Bias” update with object movement?
- Feature-location binding in 3D: Feature judgments are biased by 2D location but not position-in-depth
- 2D location biases depth-from-disparity judgments but not vice versa
- Object-location binding across a saccade: A retinotopic Spatial Congruency Bias
- The influence of spatial location on same–different judgments of facial identity and expression
- The dominance of spatial information in object identity judgments: A persistent congruency bias even amidst conflicting statistical regularities
- The development of visual cognition: The emergence of spatial congruency bias
- The influence of object location on identity: A “spatial congruency bias”
Neural representations for visual processing
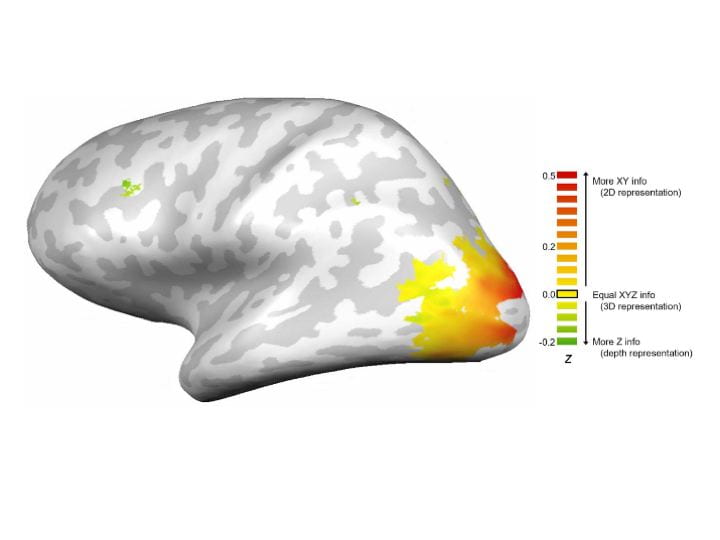 More broadly, we are interested in how spatial locations and relationships are coded in the brain, and how these representations are influenced by attention and other top-down factors. The brain is known to contain several “maps” of visual space, but an open question is whether these representations reflect simply the location on the retina, or if some brain regions represent more ecologically relevant coordinate systems. Recent work in the lab has used fMRI multivariate pattern analysis to decode whether representations in different parts of the brain are retinotopic or spatiotopic, as well as combinations of fMRI and EEG to explore how these representations are dynamically updated across eye movements and other shifts of internal and external attention. Another line of work in the lab has focused on the emergence of 3D spatial representations in the brain. We also collaborate with multiple other labs to explore the neural mechanisms of face perception, scene processing, and working memory. Check out these:
More broadly, we are interested in how spatial locations and relationships are coded in the brain, and how these representations are influenced by attention and other top-down factors. The brain is known to contain several “maps” of visual space, but an open question is whether these representations reflect simply the location on the retina, or if some brain regions represent more ecologically relevant coordinate systems. Recent work in the lab has used fMRI multivariate pattern analysis to decode whether representations in different parts of the brain are retinotopic or spatiotopic, as well as combinations of fMRI and EEG to explore how these representations are dynamically updated across eye movements and other shifts of internal and external attention. Another line of work in the lab has focused on the emergence of 3D spatial representations in the brain. We also collaborate with multiple other labs to explore the neural mechanisms of face perception, scene processing, and working memory. Check out these:
- Neural representations of space, features, and attention across eye movements
- Higher-level visual cortex represents retinotopic, not spatiotopic, object location
- Eye movements help link different views in scene-selective cortex
- No evidence for automatic remapping of stimulus features or location found with fMRI
- Attentional facilitation throughout human visual cortex lingers in retinotopic coordinates after eye movements
- Neural representations of covert attention across saccades: comparing pattern similarity to shifting and holding attention during fixation
- Dynamic neural reconstructions of attended object location and features using EEG
- Gaze-centered spatial representations in human hippocampus.
- Neural representations of 3D space
- Differential patterns of 2D location versus depth decoding along the visual hierarchy
- Category-selective areas in human visual cortex exhibit preferences for stimulus depth
- Representations of 3D visual space in human cortex: Population receptive field models of position-in-depth
- Decoding 3D spatial location across saccades in human visual cortex
- Neural representations of faces, places, & things
- Neuroimaging analysis development
- An enhanced inverted encoding model for neural reconstructions
- Dynamic neural reconstructions of attended object location and features using EEG
- Generate your neural signals from mine: individual-to- individual EEG converters
- ReAlnet: Achieving More Human Brain-Like Vision via Human Neural Representational Alignment
- Human EEG and artificial neural networks reveal disentangled representations of object real-world size in natural images
Attention and working memory
 Finally, our lab explores the mechanisms and interactions of attention and working memory more generally. Much of our work described above on attentional remapping and dynamic attention / feature-binding involves manipulations of attention sustained via working memory, and/or uses behavioral paradigms common to the working memory literature. Our research also aims to understand the intricate interactions between attention, perception, and working memory. What is the relationship between external and internal attention? Do visual representations held in working memory interact with each other? Are the processing filters regulating perception, attention, and working memory similarly disrupted when we get distracted? Check out :
Finally, our lab explores the mechanisms and interactions of attention and working memory more generally. Much of our work described above on attentional remapping and dynamic attention / feature-binding involves manipulations of attention sustained via working memory, and/or uses behavioral paradigms common to the working memory literature. Our research also aims to understand the intricate interactions between attention, perception, and working memory. What is the relationship between external and internal attention? Do visual representations held in working memory interact with each other? Are the processing filters regulating perception, attention, and working memory similarly disrupted when we get distracted? Check out :
- Theoretical reviews and commentaries:
- Visual memory representations and distortions
- Distraction, Suppression, and the Filter Disruption Theory
- Attentional capture alters feature perception
- Perceptual distraction causes visual memory encoding intrusions
- Visual distraction disrupts category-tuned filters in ventral visual cortex
- Suppression of a salient distractor protects the processing of target features
- Learned spatial suppression is not always proactive