proper link to the python 3.3 tutorial
A bit of music to code by:
DJ DARKHORSE : MIXTAPE N° 188 by The Voice Of Cassandre on Mixcloud
some screenshots I’d like to save:




proper link to the python 3.3 tutorial
A bit of music to code by:
DJ DARKHORSE : MIXTAPE N° 188 by The Voice Of Cassandre on Mixcloud
some screenshots I’d like to save:
finishing up Alice and word count (exercise 7):
![]()
from the python tutorial: tutorial
all of these values will set up a dictionary
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
a == b == c == d == e
creating our dict:

adding to it:

from the tutorial:

import os
countX = 0
countA = 0
countB = 0
dirX = "Fisher"
listA = os.listdir(dirX)
countX += 1
for itemB in listA:
pathC = dirX + "/" + itemB
listD = os.listdir(pathC)
countA += 1
for itemE in listD:
pathF = pathC + "/" + itemE
itemG = open(pathF)
countB += 1
for fileH in itemG:
outputI = len(fileH)
print()
print(dirX)
print(itemB)
print(itemE)
print(itemG)
print(outputI)
print()
print(" lines/items in --")
print(" -- Fisher =", countX)
print(" -- Fisher/.. =", countA)
print(" -- Fisher/../.. =", countB)
print()
module.fuction("argument")
here,
module = os
funtion = listdir
argument = path
so…
import os
os.listdir("Fisher")
# This is a relative path (relative to where I am)\
which director I start in
>>> fisherFile = open("Fisher/065/fe_03_06500.txt")
Creates a file object
“tail” in Unix prints ~ the last ten lines of a flie
(use as such):
tail "Fisher/065/fe_03_06500.txt"
this code to count the number of words by gender:
# ----- initialization of tracking variables ----- #
totalWordsSpoken = 0
totalUtterances = 0
wordsW = 0
wordsM = 0
wordsN = 0
utterW = 0
utterM = 0
utterN = 0
# ----- opening file ----- #
fF = open("../Downloads/Fisher/065/fe_03_06500.txt")
# ----- for loop ----- #
for sentence in fF:
# ----- processing block ----- #
words = sentence.split()
onlywords = words[3:]
genderLetter = words[2][2]
speakerID = words[2][0]
numberwords = len(onlywords)
onlysen = " ".join(onlywords)
# ----- count ----- #
totalWordsSpoken += numberwords
totalUtterances += 1
# ----- gender output ----- #
if genderLetter == 'f':
gender = "woman"
wordsW += numberwords
utterW += 1
elif genderLetter == 'm':
gender = "man"
wordsM += numberwords
utterM += 1
else:
gender = "non-gendered person"
wordsN = numberwords
utterN += 1
# ----- output per sentence----- #
print()
print(" ", "sentence number", totalUtterances, ":", onlysen)
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is a:", gender)
# ----- final totals output ----- #
print()
print(" ", "total number of words:", totalWordsSpoken)
print(" ", "total number of utterances:", totalUtterances)
print(" ", "the average number of words per utterance was :",
totalWordsSpoken / totalUtterances)
print()
print(" ", "total words spoken by women:", wordsW)
print(" ", "total number of utterances:", utterW)
print(" ", "the average number of words per utterance was :",
wordsW / utterW)
print()
print(" ", "total words spoken by men:", wordsM)
print(" ", "total number of utterances:", utterM)
print(" ", "the average number of words per utterance was :",
wordsM / utterM)
print()
print(" ", "total words unaccounted for by gender:", wordsN)
print(" ", "total number of utterances unaccounted for:", utterN)
print()
returns this result:

how do we check that our output is correct? Count them manually?
Python (if installed properly) always tells the terminal where it is located, so, relative to Python, the program doesn’t need to be in the same directory, or even referenced in relation to it.
![]()
*/ — set up Cygwin on the Dellosaurus to do the same thing, if possible? — /*
First program (in Xcode on mac):
returns this output in Python 3.3.4 in Terminal:

because the program is processed in a linear order, we can change the value of “sentence” at any point after where it was initially set

but if you don’t redefine the other variables, it returns:

redefining the variables for the second sentence:

you get the correct, expected output, and the correct number count:

I wonder if there is a more concise way to do this, or maybe I’m doing it incorrectly?
the for loop
unlike other programming languages, Python uses indentation to define the scope of the loop (not {} like some, etc.)
to start counting, we have to set the total to 0 so that we can mark it as an integer, and have a starting point
the loop runs in the interactive mode in Python:
# -- for loop
for number in [1, 2, 3]:
number *= 2
print(number)
# -- processing 1
number = 1
number *= 2
print(number)
# -- processing 2
number = 2
number *= 2
print(number)
# -- processing 3
number = 3
number *= 2
print(number)
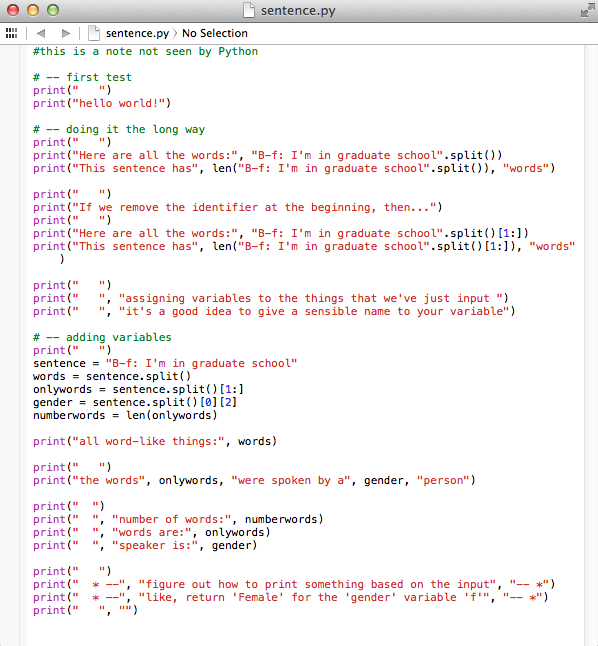
in class programs:
sentence.py
#this is a note not seen by Python
# -- first test
# print(" ")
# print("hello world!")
# -- doing it the long way (sentence 1)
# print(" ")
# print("Here are all the words:", "B-f: I'm in graduate school".split())
# print("This sentence has", len("B-f: I'm in graduate school".split()), "words")
# print(" ")
# print("If we remove the identifier at the beginning, then...")
# print(" ")
# print("Here are all the words:", "B-f: I'm in graduate school".split()[1:])
# print("This sentence has", len("B-f: I'm in graduate school".split()[1:]), "words")
# print(" ")
# print(" ", "assigning variables to the things that we've just input ")
# print(" ", "it's a good idea to give a sensible name to your variable")
# -- adding variables (sentence 1)
print(" ")
sentence = "B-f: I'm in graduate school"
words = sentence.split()
onlywords = words[1:]
gender = words[0][2]
speakerID = words[0][0]
numberwords = len(onlywords)
# print("all word-like things:", words)
# print(" ")
# print("the words", onlywords, "were spoken by a", gender, "person")
print(" ", "for the sentence,", sentence)
print(" ")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
# print(" ")
# print(" * --", "figure out how to print something based on the input", "-- *")
# print(" * --", "like, return 'Female' for the 'gender' variable 'f'", "-- *")
# print(" ", "")
# -- looking at a second sentence (sentence 2): changing the value of "sentence", and re-running everything
# -- taking the whole thing out of the print (after the fact)
print(" ")
sentence = "B-f: at OSU"
words = sentence.split() # only need to redefine the "words" variable
# -- don't need to redefine the other variables
print(" ", "for the sentence,", sentence)
print(" ")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
print(" ")
# -- initialization of tracking variables
totalWordsSpoken = 0
totalUtterances = 0
# -- adding variables (sentence 1)
print(" ")
sentence = "B-f: I'm in graduate school"
words = sentence.split()
onlywords = words[1:]
gender = words[0][2]
speakerID = words[0][0]
numberwords = len(onlywords)
totalWordsSpoken += len(onlywords)
totalUtterances += 1
print(" ", "sentence 1")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
# -- sentence 2
print(" ")
sentence = "B-f: at OSU"
words = sentence.split() # define these variables again
onlywords = words[1:]
gender = words[0][2]
speakerID = words[0][0]
numberwords = len(onlywords)
totalWordsSpoken += len(onlywords)
totalUtterances += 1
print(" ", "sentence 2")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
# -- final output
print(" ")
print(" ", "total number of words:", totalWordsSpoken)
print(" ", "total number of utterances:", totalUtterances)
print(" ", "the average number of words per utterance was :",
totalWordsSpoken / totalUtterances)
print(" ")
notes
need to use escape characters for some elements
if you are using single quotes for something other than delimiting the string, it needs to be marked as unique — not a command
>>> 'I\'m in graduate school'
length = takes an argument and returns the length of the string
>>> len("hello")
5
len = length
int = integer
str = string (by convention, we put a string between quotes – single or double)
type = will return one of these data types
>>> type("hello")
<class 'str'>
the dot ” . ” connects the string with
>>> "I'm in graduate school".split()
["I'm", 'in', 'graduate', 'school']
>>> len(["I'm", 'in', 'graduate', 'school'])
4
>>> len("I'm in graduate school".split())
4
in lists, the elements are ordered, Python starts with [0]
The number in brackets is called the index, and points to a specific element within the list
>>> "I'm in graduate school".split()[3] 'school' >>>
here’s an exciting oddity that I accidentally discovered:
>>> "I'm in graduate school".split()[2][3] 'd'
the second index returns the third character within the second element split from the string
Ctrl+C will escape you from Python back to cmd (or Terminal, as the case may be)
more v less — there is less difference between them on the mac, but you can still see the output in Terminal after you quit if you use more, but the output disappears if you use less
-lh = lists the files with the additional metadata (time created, etc.)
wc shows:
lines words bytes file_name.txt
![]()
And from the manual:

| “pipe” – from the pdf :
We use the vertical bar “|” to connect two commands together so that the output from one command becomes the input of the next command. Two (or more) commands connected in this way form what’s called a pipe.
regular expression
grep = going to count the number of lines that some element we are looking for appears in
useful for looking for a word in a file
to get out, type Ctrl+C or Ctrl+D
grep returns the number of lines, and when you conjoin it with “wc” ( via | ), it counts the number of words in each line that contains the expression that you were searching for, NOT the number of instances of the expression itself.
grep –color=auto”[laughter]” will return each character that matches those in brackets. (the brackets have a particular function in regular)
if you type “grep” in with nothing else, you get a list of available commands.
$ man ls — manual about the operator “ls”
to exit, once in the manual — type “q”
most of the applications that can run in terminal won’t respond to the mouse (i.e. scrolling), but will respond to the keyboard
cd = change directory (like cmd prompt in windows)
pwd = shows which directory you are in (the address/location) — “pathname working directory”
directories in a computer looks just like a syntax tree — hierarchy
Downloads
Fisher
058
fe_03_05851.txt
fe_03_05852.txt
etc.
065
.. = move up one level in the hierarchy
can combine these elements for efficiency: cd ../065 (if you’re in 058, for example)
cd without an argument will take you back to the home directory. (all the way back up the hierarchy)
more = open text files (look into) text files
less = same command as “more” — ‘less is more’ but it allows backward as well as forward movement in the file
wc = word, line, character, and byte count