over the weekend coding music… well, I guess this is debugging music, really.
some more coding music:
Joe Acheson (Hidden Orchestra) – Archipelago Mixtape by Tru Thoughts on Mixcloud
over the weekend coding music… well, I guess this is debugging music, really.
some more coding music:
Joe Acheson (Hidden Orchestra) – Archipelago Mixtape by Tru Thoughts on Mixcloud
tasks in the homework:
We want to address the question of whether women talk more than men. To answer this, we will use the Fisher corpus on Carmen.
Write a python script that outputs —
- the raw total number of words spoken by women
- the raw total number of words spoken by men
- the total number of utterances spoken by women
- the total number of utterance spoken by men
- the average number of words per utterance spoken by women and by men
- the number of female speakers
- the number of male speakers
the previous assignment plus opening the Fisher files with nested ‘for’ loops gives:

which is the output of this loop (so far) written in class:
# ------ importing all directories ----- #
import os
# ----- initialization of tracking variables ----- #
totalWordsSpoken = 0
totalUtterances = 0
wordsW = 0
wordsM = 0
wordsN = 0
utterW = 0
utterM = 0
utterN = 0
# ----- listing top-level directory ----- #
dir = "Fisher"
dirA = os.listdir(dir)
# ----- listing subdirectories ----- #
for dirB in dirA:
dirC = dir + "/" + dirB
fileA = os.listdir(dirC)
# ----- opening files ----- #
for fileB in fileA :
path = dirC + "/" + fileB
fileC = open(path)
# ----- for loop ----- #
for sentence in fileC:
# ----- processing block ----- #
words = sentence.split()
onlywords = words[3:]
genderLetter = words[2][2]
speakerID = words[2][0]
numberwords = len(onlywords)
onlysen = " ".join(onlywords)
# ----- count ----- #
totalWordsSpoken += numberwords
totalUtterances += 1
# ----- gender output ----- #
if genderLetter == 'f':
gender = "woman"
wordsW += numberwords
utterW += 1
elif genderLetter == 'm':
gender = "man"
wordsM += numberwords
utterM += 1
else:
gender = "non-gendered person"
wordsN = numberwords
utterN += 1
# ----- output per sentence----- #
print()
print(" ", "sentence number", totalUtterances, ":", onlysen)
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is a:", gender)
# ----- final totals output ----- #
print()
print(" ", "total number of words:", totalWordsSpoken)
print(" ", "total number of utterances:", totalUtterances)
print(" ", "the average number of words per utterance was :",
totalWordsSpoken / totalUtterances)
print()
print(" ", "total words spoken by women:", wordsW)
print(" ", "total number of utterances:", utterW)
print(" ", "the average number of words per utterance was :",
wordsW / utterW)
print()
print(" ", "total words spoken by men:", wordsM)
print(" ", "total number of utterances:", utterM)
print(" ", "the average number of words per utterance was :",
wordsM / utterM)
print()
print(" ", "total words unaccounted for by gender:", wordsN)
print(" ", "total number of utterances unaccounted for:", utterN)
print()
need to add some stuff in to count the number of speakers of each gender.
having a bit of trouble with the if/else statements here and the nesting. I’m going to build a code for only one file, extend it to two, and then run it on the entire corpus once I can differentiate between the ‘A-f:’ in one file, and the ‘A-f:’ in the next file in the list. I’m also assuming that there are never any repeated speakers across files.
Here are the counts for fe_03_06500.txt to compare the code against:
(there is 1 female speaker, and 1 male speaker.

here is my speaker count abstraction (I’m sure there’s an easier way to do this):
# --- babyHW1.py --- #
# --- instantiate --- #
a = 13 #w
b = 0 #w
c = 2 #m
d = 9 #m
e = 0 #n
w = 0
m = 0
n = 0
# --- speaker count --- #
if a > 0:
w += 1
else:
w = 0
if b > 0:
w += 1
else:
w = 0
if c > 0:
m += 1
else:
m = 0
if d > 0:
m += 1
else:
m = 0
if e > 0:
n += 1
else:
n = 0
# --- output --- #
print("w:", w)
print("m:", m)
print("n:", n)
In class, we have seen how to read from a file. Here is what the code looks like so far:
#------------initialization of tracking variables-------------------
totalWordsSpoken = 0
totalUtterances = 0
#------------open the file-------------------------
fisherFile = open("Fisher/065/fe_03_06500.txt")
#-----------processing block---------------------
for line in fisherFile:
#list of the items in the line
words = line.split()
print("Here are all the words", words)
#extracting speaker ID
speaker = words[2]
#actual words uttered by the speaker
actualWords = words[3:]
print("the sentence is spoken by", speaker)
print("their actual utterance was", actualWords)
print("the sentence has", len(actualWords), "words")
totalWordsSpoken += len(actualWords)
totalUtterances += 1
#---------done with all the sentences; post-analysis----------
print("the total number of words spoken was", totalWordsSpoken)
print("the total number of utterances was", totalUtterances)
print("the average number of words per utterance was",
totalWordsSpoken / totalUtterances)
Now we want to keep track of the gender information too. We want the total of words and the total of utterances uttered by women as well as the total of words and the total of utterances uttered by men. Look at the notes and adapt your code to use a “if statement” to do so. Make sure your code runs ;-) The notes give the results.
wrote this code in class (see Python scripting)
# ----- initialization of tracking variables ----- #
totalWordsSpoken = 0
totalUtterances = 0
wordsW = 0
wordsM = 0
wordsN = 0
utterW = 0
utterM = 0
utterN = 0
# ----- opening file ----- #
fF = open("../Downloads/Fisher/065/fe_03_06500.txt")
# ----- for loop ----- #
for sentence in fF:
# ----- processing block ----- #
words = sentence.split()
onlywords = words[3:]
genderLetter = words[2][2]
speakerID = words[2][0]
numberwords = len(onlywords)
onlysen = " ".join(onlywords)
# ----- count ----- #
totalWordsSpoken += numberwords
totalUtterances += 1
# ----- gender output ----- #
if genderLetter == 'f':
gender = "woman"
wordsW += numberwords
utterW += 1
elif genderLetter == 'm':
gender = "man"
wordsM += numberwords
utterM += 1
else:
gender = "non-gendered person"
wordsN = numberwords
utterN += 1
# ----- output per sentence----- #
print()
print(" ", "sentence number", totalUtterances, ":", onlysen)
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is a:", gender)
# ----- final totals output ----- #
print()
print(" ", "total number of words:", totalWordsSpoken)
print(" ", "total number of utterances:", totalUtterances)
print(" ", "the average number of words per utterance was :",
totalWordsSpoken / totalUtterances)
print()
print(" ", "total words spoken by women:", wordsW)
print(" ", "total number of utterances:", utterW)
print(" ", "the average number of words per utterance was :",
wordsW / utterW)
print()
print(" ", "total words spoken by men:", wordsM)
print(" ", "total number of utterances:", utterM)
print(" ", "the average number of words per utterance was :",
wordsM / utterM)
print()
print(" ", "total words unaccounted for by gender:", wordsN)
print(" ", "total number of utterances unaccounted for:", utterN)
print()
which returns this output on the macs at school (haven’t tried it at home yet)

Python (if installed properly) always tells the terminal where it is located, so, relative to Python, the program doesn’t need to be in the same directory, or even referenced in relation to it.
![]()
*/ — set up Cygwin on the Dellosaurus to do the same thing, if possible? — /*
First program (in Xcode on mac):
returns this output in Python 3.3.4 in Terminal:

because the program is processed in a linear order, we can change the value of “sentence” at any point after where it was initially set

but if you don’t redefine the other variables, it returns:

redefining the variables for the second sentence:

you get the correct, expected output, and the correct number count:

I wonder if there is a more concise way to do this, or maybe I’m doing it incorrectly?
the for loop
unlike other programming languages, Python uses indentation to define the scope of the loop (not {} like some, etc.)
to start counting, we have to set the total to 0 so that we can mark it as an integer, and have a starting point
the loop runs in the interactive mode in Python:
# -- for loop
for number in [1, 2, 3]:
number *= 2
print(number)
# -- processing 1
number = 1
number *= 2
print(number)
# -- processing 2
number = 2
number *= 2
print(number)
# -- processing 3
number = 3
number *= 2
print(number)
in class programs:
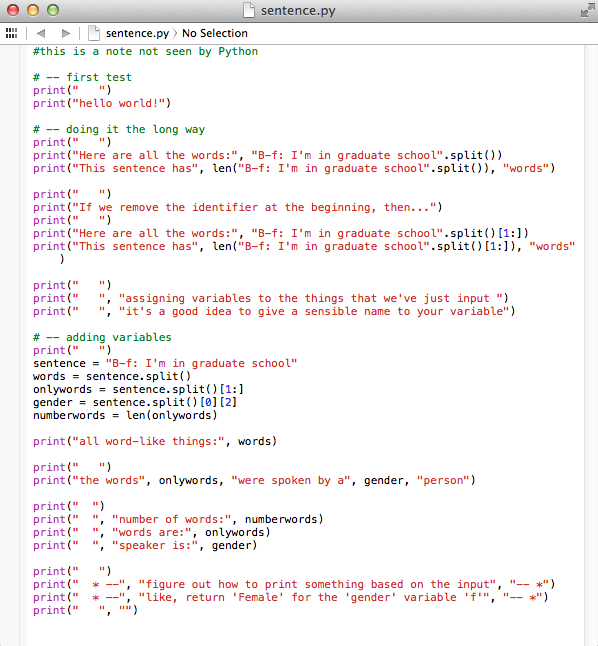
sentence.py
#this is a note not seen by Python
# -- first test
# print(" ")
# print("hello world!")
# -- doing it the long way (sentence 1)
# print(" ")
# print("Here are all the words:", "B-f: I'm in graduate school".split())
# print("This sentence has", len("B-f: I'm in graduate school".split()), "words")
# print(" ")
# print("If we remove the identifier at the beginning, then...")
# print(" ")
# print("Here are all the words:", "B-f: I'm in graduate school".split()[1:])
# print("This sentence has", len("B-f: I'm in graduate school".split()[1:]), "words")
# print(" ")
# print(" ", "assigning variables to the things that we've just input ")
# print(" ", "it's a good idea to give a sensible name to your variable")
# -- adding variables (sentence 1)
print(" ")
sentence = "B-f: I'm in graduate school"
words = sentence.split()
onlywords = words[1:]
gender = words[0][2]
speakerID = words[0][0]
numberwords = len(onlywords)
# print("all word-like things:", words)
# print(" ")
# print("the words", onlywords, "were spoken by a", gender, "person")
print(" ", "for the sentence,", sentence)
print(" ")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
# print(" ")
# print(" * --", "figure out how to print something based on the input", "-- *")
# print(" * --", "like, return 'Female' for the 'gender' variable 'f'", "-- *")
# print(" ", "")
# -- looking at a second sentence (sentence 2): changing the value of "sentence", and re-running everything
# -- taking the whole thing out of the print (after the fact)
print(" ")
sentence = "B-f: at OSU"
words = sentence.split() # only need to redefine the "words" variable
# -- don't need to redefine the other variables
print(" ", "for the sentence,", sentence)
print(" ")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
print(" ")
# -- initialization of tracking variables
totalWordsSpoken = 0
totalUtterances = 0
# -- adding variables (sentence 1)
print(" ")
sentence = "B-f: I'm in graduate school"
words = sentence.split()
onlywords = words[1:]
gender = words[0][2]
speakerID = words[0][0]
numberwords = len(onlywords)
totalWordsSpoken += len(onlywords)
totalUtterances += 1
print(" ", "sentence 1")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
# -- sentence 2
print(" ")
sentence = "B-f: at OSU"
words = sentence.split() # define these variables again
onlywords = words[1:]
gender = words[0][2]
speakerID = words[0][0]
numberwords = len(onlywords)
totalWordsSpoken += len(onlywords)
totalUtterances += 1
print(" ", "sentence 2")
print(" ", "number of words:", numberwords)
print(" ", "words are:", onlywords)
print(" ", "speaker ID:", speakerID)
print(" ", "speaker is:", gender)
# -- final output
print(" ")
print(" ", "total number of words:", totalWordsSpoken)
print(" ", "total number of utterances:", totalUtterances)
print(" ", "the average number of words per utterance was :",
totalWordsSpoken / totalUtterances)
print(" ")
(a) Quantifying the data in the Fisher corpus
How many utterances and words do we have in the Fisher corpus on Carmen?
files in Fisher:

wcs in Fisher:
065
![]()
058
![]()
total lines/”utterances” in Fisher (math in Python):
![]()
total words in Fisher (math in Python):

29734 utterances
362020 words
in class
forgot to subtract the time-stamps and the markers for the words — perhaps the best way to do this would be to multiply the number of total number lines by three, and then subtract those non-words (three in each line) from the total number of words.
(b) Do people laugh?
What is the percentage of utterances containing laughter, totaling all the files of the “058” directory?
utterances containing laughter in Fisher (directions from the pdf):

from Cygwin:

the number of lines 1681 is the number of “utterances” with laughter in all of Fisher
utterances in only 058:
![]()
utterances with laughter in only 058:

using different commands returned the same number of lines, but different numbers of bytes. Is it the “-R” that changed it?
10556 utterances in 058
199 utterances in 058 containing [laughter]
percentage of utterance containing [laughter] in 058 (math in Python):
![]()
approx 1.9% of the utterances in 058 contain laughter.
So, here is the stylesheet I’ve introduced (mega-basic)
<head>
<style>
body { font-family: Lucida Console,Monaco,monospace; }
a { text-decoration: none; }
pre, blockquote { font-size: 13px; }
</style>
</head>
It overrides a few elements, but still needs <blockuote> to be styled inline.
It also doesn’t extend font-size to the footer, or text-decoration to the sidebar links (although the calendar does lose it’s underline)
I tried to put the whole thing on one line, attempting to remove the giant gap at the top, but it doesn’t work. the <head> tag is the culprit. I think I’ll need to adjust the margins, but I should look into the original stylesheet first. OR… hack away!
added:
margin-top { font-size: -10px; }
It seemed to work, but not enough. Changed to -100px. Let’s see. Nuthin’. Moved the margin-top within the body identifier. And?? not much. -300px? Oh my! I chopped off the whole top of the blog! Check it out:

let’s try padding instead. (I can’t remember, is that only for HTML tables?). Nuthin’. How do I hide the <head> tag then? This is a job for later. Other things to do. Taking the whole margin thing out.
Or maybe wrap the whole thing in a <div>? As an idea, and move it up… but since <head> is technically inside the &tl;body>, that makes things odd.
HERE is the global stylesheet, so I know where to start hijacking… begin with the GIgantic h1 and h2 perhaps?
Also, later, will want to explore:
... into … ...
kinda what I thought.
the following is a test of the “close tags” feature:
make sure when adding images to the site, the size is set to “full-size”, and the alignment is “none”. If the alignment is set at all, the words will wrap, and it will be impossible to start a new paragraph just below. But, if wrapping is what you’re after… go for it.
earlier ideas
It may be that it only works on the “home” page — need to test that out.
Oooh, maybe I can add every tag to “hackarooni”… but it might be ugly. humph.
Update2: nope – need to put it in every post, so that if you click on just the link to that post, it’ll stay formatted. Rrrrrr.
<body style="font-family:Lucida Console,Monaco,monospace;">
<pre style="font-size:13px;"> <blockquote style="font-size:13px;"> <a style="text-decoration:none;">
and here, HERE, friends, we will test the special characters *crosses fingers* c’moooonnnn!!
first, outside the preformatting : ə æ g͡bɛ k͡pɪŋɑ
and then, within :
ə æ g͡bɛ k͡pɪŋɑ
NICE, WordPress!
here, one invoking a special (but still webbish) font — okay, so it’s Times New Roman, but whatever, and 18px font-size:
ə æ g͡bɛ k͡pɪŋɑ